什么是 Robots.txt?| Robots.txt 文件的工作原理
Robots.txt 文件包含针对机器人的说明,该说明告诉机器人哪些网页可以和不可以访问。Robots.txt 文件与Google等搜索引擎的网页爬网程序关联最直接。
学习目标
阅读本文后,您将能够:
- 了解什么是 robots.txt 文件及其作用
- 了解机器人如何与 robots.txt 文件进行交互
- 探索 robots.txt 文件中使用的协议,包括机器人排除协议和站点地图
复制文章链接
使用 Cloudflare 解决方案,抵御凭据填充和内容抓取之类的机器人攻击
什么是 robots.txt?

Robots.txt 文件是针对机器人的一组指令。该文件包含在大多数网站的源文件中。Robots.txt 文件主要用于管理 Web 爬网程序类的良性机器人活动,因为恶意机器人不太可能遵循这些说明。
可以将 robots.txt 文件视为贴在健身房、酒吧或社区中心墙上的"行为准则"标牌:标牌本身无权执行所列规则,但"有素质"的顾客将遵守规则,而"没有素质的"顾客可能会打破规则并被驱逐。
机器人是与网站和应用程序交互的自动化计算机程序。有良性机器人也有恶意机器人,有一种良性机器人称为网络爬虫机器人。这些机器人会对网页进行“爬网”并为内容建立索引,以便其可以显示在搜索引擎结果中。robots.txt 文件可帮助管理这些网页爬网程序的活动,以使它们不会增加托管该网站的 Web 服务器的负担或索引不想被公开的页面。
Robots.txt 文件如何工作?
Robots.txt 文件只是一个没有 HTML 标记代码的文本文件(因此扩展名为 .txt)。robots.txt 文件与网站上的任何其他文件一样,都托管在网络服务器上。实际上,通常可以通过输入主页的完整 URL,然后添加 /robots.txt 来查看任何给定网站的 robots.txt 文件,例如 https://www.cloudflare.com/robots.txt。该文件未链接到网站上的任何其他位置,因此用户不太可能会偶然发现该文件,但是大多数网页爬网程序机器人都会在抓取该网站的其余部分之前先查找该文件。
虽然 robots.txt 文件提供了有关机器人的规范,但实际上并不能执行这些规范。良性的机器人(例如网页爬网程序或新闻提要机器人)将先尝试访问 robots.txt 文件,然后再查看域中的任何其他页面,并将按照说明进行操作。恶意的机器人忽略 robots.txt 文件或对其进行处理,以查找被禁止的网页。
网页爬网程序机器人将遵循 robots.txt 文件中最具体的指示集。如果文件中有矛盾的命令,则机器人将遵循更细化的命令。
要注意的一件事是,所有子域都需要有自己的 robots.txt 文件。例如,尽管 www.cloudflare.com 拥有自己的文件,但所有 Cloudflare 子域(blog.cloudflare.com,community.cloudflare.com等)也需要它们自己的文件。
Robots.txt 文件中使用了哪些协议?
在网络中,协议是用于提供指令或命令的格式。Robots.txt 文件使用几种不同的协议。主要协议称为“机器人排除协议 (Robots Exclusion Protocol)”。这是一种告诉机器人避免使用哪些网页和资源的方法。robots.txt 文件中包含为此协议格式化的说明。
用于 robots.txt 文件的其他协议是 Sitemaps 协议。这可以视为机器人包含协议。站点地图会向网络抓取工具显示其可以抓取的页面。这有助于确保网页爬网程序机器人不会遗漏任何重要页面。
Robots.txt 文件示例
这是 www.cloudflare.com 的 robots.txt 文件:
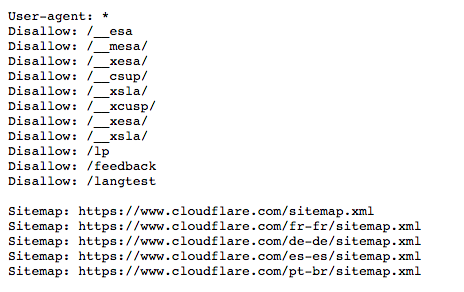
下面我们将分解所有这些含义。
什么是用户代理?“User-agent: *”(用户代理)是什么意思?
在互联网上活动的任何人或程序都将有"用户代理"或分配的名称。对于人类用户,这包括诸如浏览器类型和操作系统版本之类的信息,但不包括个人信息。它可以帮助网站显示与用户系统兼容的内容。对于机器人,用户代理(理论上)可帮助网站管理员了解哪种机器人正在爬网该网站。
在 robots.txt 文件中,网站管理员可以通过为机器人用户代理编写不同的说明来为特定机器人提供特定说明。例如,如果管理员希望某个页面显示在 Google 搜索结果中而不显示在 Bing 搜索结果中,则它们可以在 robots.txt 文件中包含两组命令:一组命令前面带有"User-agent: Bingbot "和另一组前面带有"User-agent: Googlebot" 。
在上面的示例中,Cloudflare在 robots.txt 文件中包含"User-agent: *" 。星号表示"通配符"用户代理,这意味着该说明适用于每个机器人,而不是任何特定机器人。
通用搜索引擎机器人用户代理名称包括:
Google:
- Googlebot
- Googlebot-Image(用于图像)
- Googlebot-News(用于新闻)
- Googlebot-Video(用于视频)
Bing
- Bingbot
- MSNBot-Media(用于图像和视频)
Baidu
- Baiduspider
“Disallow”(禁止)命令在 robots.txt 文件中的工作原理是什么?
Disallow 命令是机器人排除协议中最常见的命令。它告诉机器人不要访问该命令之后的网页或一组网页。不允许的页面不一定是“隐藏的”——它们只是对普通的谷歌或 Bing 用户没有用,因此不会显示给他们。在大多数情况下,网站上的用户如果知道在哪里可以找到它们,仍然可以导航到这些页面。
Disallow命令可以通过多种方式使用,上面的示例中显示了几种方式。
阻止一个文件(换言之,也就是一个特定的网页)
例如,如果 Cloudflare 希望阻止机器人爬取我们的文章“什么是机器人?”,那就会编写如下的命令:
Disallow: /learning/bots/what-is-a-bot/在"Disallow"命令之后,包含了主页–在本例中为"www.cloudflare.com"–之后的网页URL部分。使用此命令后,良性机器人将无法访问https://www.cloudflare.com/learning/bots/what-is-a-bot/,并且该页面也不会显示在搜索引擎结果中。
阻止一个目录
有时一次阻止多个页面比单独列出所有页面更有效。如果它们都在网站的同一部分中,robots.txt 文件可以直接阻止包含它们的目录。
还是利用上面的示例:
Disallow: /__mesa/这意味着__ mesa目录中包含的所有页面都不应被爬网。
允许完全访问
这样的命令以如下方式呈现:
Disallow:这是告诉机器人可以浏览整个网站,因为没有任何页面是不允许访问的。
向机器人隐藏整个网站
Disallow: /这里的"/"表示一个网站层次结构的"根",或者其它分支页面的上层来源,所以它包括主页和所有从它链接出去的网页。使用此命令,搜索引擎机器人完全无法抓取该网站。
换句话说,一个斜杠可以从可搜索的互联网中删除整个网站!
机器人排除协议还包含哪些其他命令?
Allow(允许):如同大家所想,“Allow”指令告诉机器人它们被允许访问特定的网页或目录。使用此命令可以允许机器人访问一个特定的网页,同时禁止文件中的其余网页。并非所有搜索引擎都能识别此命令。
Crawl-delay(抓取延迟):抓取延迟命令用于防止搜索引擎蜘蛛机器人使服务器负担过重。它允许管理员指定机器人在每个请求之间应等待的时间(以毫秒为单位)。一个等待8毫秒的抓取延迟命令的示例如下:
Crawl-delay: 8尽管其他搜索引擎可以识别,但谷歌无法识别此命令。对于谷歌,管理员可以在Google Search Console中更改其网站的抓取频率。
什么是 Sitemaps(站点地图)协议?为什么将它包含在 robots.txt 中?
Sitemaps 协议可帮助机器人知道它要爬网的网站内容。
站点地图是一个如下所示的XML文件:
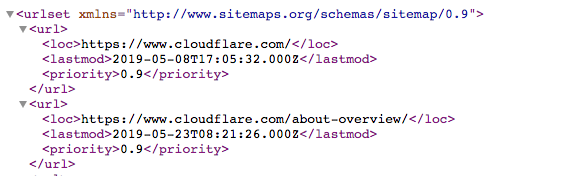
这是一份机器可读的网站上所有页面列表。通过 Sitemaps 协议,指向这些 Sitemaps 的链接可以包含在 robots.txt 文件中。格式为:"Sitemaps:"后面加上 XML 文件的网址。您可以在上面的 Cloudflare robots.txt 文件中看到几个示例。
虽然 Sitemaps 协议有助于确保网络蜘蛛机器人在爬网网站时不会错过任何内容,但它们仍将遵循其典型的爬网过程。站点地图不会强制网页爬网程序机器人以不同的方式对网页进行优先级排序。
Robots.txt与机器人管理有何关系?
管理机器人对于保持网站或应用程序的正常运行至关重要,因为即使良好的机器人活动也可能会使源站服务器负担过重进而减慢或关闭 web 资产。结构良好的 robots.txt 文件可让网站针对 SEO 进行优化,并且可控制良好的机器人活动。
但是,robots.txt 文件对管理恶意机器人流量并没有多大帮助。诸如 Cloudflare 机器人管理或 Super Bot Fight 模式之类的机器人管理解决方案可以帮助遏制恶意机器人活动,而不会影响诸如 Web 爬网程序之类的基本机器人。
Robots.txt 复活节彩蛋
有时,robots.txt 文件会包含复活节彩蛋——开发人员包含的幽默信息,因为他们知道用户很少看到这些文件。例如,YouTube robots.txt 文件中写道:“Created in the distant future (the year 2000) after the robotic uprising of the mid 90's which wiped out all humans.(在 90 年代中期机器人起义消灭了所有人类之后,在遥远的未来(2000 年)创建。)”Cloudflare robots.txt 文件则写到,“Dear robot, be nice.(亲爱的机器人,友好一点。)”
# .__________________________.
# | .___________________. |==|
# | | ................. | | |
# | | ::[ Dear robot ]: | | |
# | | ::::[ be nice ]:: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | ,|
# | !___________________! |(c|
# !_______________________!__!
# / \
# / [][][][][][][][][][][][][] \
# / [][][][][][][][][][][][][][] \
#( [][][][][____________][][][][] )
# \ ------------------------------ /
# \______________________________/
Google 在以下位置还有“humans.txt”文件:https://www.google.com/humans.txt